(Ch 3) 변수와 벡터
2024. 8. 18. 15:38ㆍ확률 통계/R 데이터 분석
산술 연산과 주석
- 다른 프로그래밍 언어와 비슷하게 산술 연산자가 존재한다.
- 또한 명령문에 대한 설명을 추가하기 위해서 ' # '을 사용하여서 주석을 달아준다.
| 연산자 | 의미 |
| + | 덧셈 |
| - | 뺄셈 |
| * | 곱셈 |
| / | 나눗셈 |
| %% | 나눗셈의 나머지 |
| ^ | 제곱 |


산술 연산 함수
| 함수 | 의미 |
| log() | 로그 함수 |
| sqrt() | 제곱근 |
| max() | 최댓값 |
| min() | 최솟값 |
| abs() | 절댓값 |
| factorial() | 팩토리얼 |
| sin(),cos(),tan() | 삼각함수 |


- 로그 함수는 상용로그로 정의되어 있고, log(숫자, base=숫자)에서 base에 해당하는 숫자를 사용하여서 밑을 변경할 수 있다.
변수
변수: R에서 변수는 주로 데이터를 저장하는데 주로 사용된다.

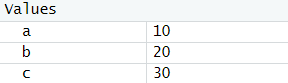
변수명 지정
- 첫 글자는 영문 또는 마침표(.)으로 시작한다.
- 두 번째 글자 이후에는 영문자, 숫자, 마침표(.), 밑줄(_)을 사용할 수 있다.
- 대문자와 소문자는 구별된다.
- 중간에 빈칸을 넣을 수 없다.
변수의 자료형
| 자료형 | 사용 예시 | 비고 |
| 솟자형 | 1,2,3,4,-5,13.4 | 정수와 실수 모두 가능 |
| 문자형 | 'Seo',"Jun" | 작은 따음표나 큰 따음표로 표현 |
| 논리형 | TRUE,FALSE | T,F로 줄여서 사용가능함 |
| 특수값 | NULL | 자료형도 없고 길이도 0 |
| NA | 결측값 | |
| NaN | 수학적으로 정의가 불가능한 값 | |
| Inf,-Inf | 양의 무한대와 음의 무한대 |


백터
백터: 데이터를 1차원 배열 형태로 저장해두는 저장소를 의미한다.
백터의 구조
x<-c(1,,2,3)
여기에서 c는 combine의 의미를 가지고, c() 함수가 여러 값을 묶어준다.


cf) 정수형과 문자형을 같이 쓴다면 정수형이 문자형으로 바뀌게 된다.

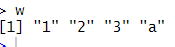
연속적인 숫자로 이루어진 벡터의 생성
콜론을 사용하여서 범위를 지정해줄 수 있다.

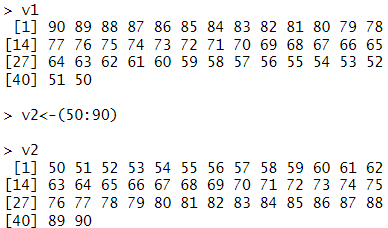
일정한 간격의 숫자로 이루어진 벡터 생성
seq(시작 값, 종료 값, 간격)으로 정수형, 실수형이 가능하다.


반복된 숫자로 이루어진 벡터 생성
rep(반복대상값, 반복 횟수)를 사용한다. times를 사용하여서 전체 데이터를 반복해 주는 횟수를 정해주고 each를 사용하여서 각각의 데이터의 반복 횟수를 설정해 줄 수 있다.


백터의 원소값에 이름 지정
names()를 활용하여서 백터 안에 있는 원소들에게 이름을 부여해줄 수 있다. 이러한 원소에 대한 이름들은 산술계산 과정에는 영향을 끼치지 않는다.


백터에서 원소값 추출
파이썬 리스트와 같이 a[1], d [12] 해주면 되지만 파이썬에서는 인덱스가 0부터 시작하지만 여기에서는 인덱스가 1부터 시작한다.


백터에서 여러개의 값을 출력하기
- d [c(1,3,5)]: 1,3,5번째 값을 출력
- d [1:3]: 1~3번째 값을 출력
- d [seq(1,5,2)]: 1~5까지의 숫자를 2의 간격을 두고 출력
- d [-c(2:4)]: 2~4의 값을 제외하고 출력


백터에서 이름으로 값을 추출하기
백터의 이름에 직접 접근하여서 값을 추출할 수 있다.
- d ["이름"]: 한 가지 원소에만 접근
- d [c("이름", "이름",...)]: 여러 가지 원소에 접근 가능

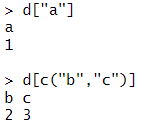
백터에 저장된 원소값 변경
- d[index]<-숫자: index번쨰 데이터를 숫자로 변경
- d [c(index1, index2)]<-c(숫자, 숫자) index 번째의 데이터를 숫자들로 변경


백터의 연산
백터의 숫자값 연산
- d-5: d 백터에 있는 원소들에게 -5 연산을 해준다.
- 2*d: d백터에 있는 원소들에게 *2연산을 해준다.


백터와 백터 간의 연산
- 각 백터들의 동일한 index를 가지는 데이터들이 연산을 수행한다.


길이가 다른 경우에도 에러없이 연산은 가능하지만 우리가 원하는 결과가 아닐 수도 있기 때문에 길이가 동일한지 확인해줘야 한다.
백터에 적용 가능한 함수
- sort(): 오름차순이 기본이고 내림차순으로 바꾸고 싶다면 decreasing=T(또는 TRUE)를 넣어주면 된다.
- range(): 백터에서 제일 작은 숫자와 제일 큰 숫자를 출력해 준다.
| 함수명 | 설명 |
| sum() | 데이터들의 합 |
| mean() | 데이터들의 평균 |
| median() | 데이터들의 중앙값 |
| max(),min() | 최댓값, 최솟값 |
| var() | 분산 |
| sd() | 표준 편차 |
| sort() | 정렬(오름 차순이 기본) |
| range() | 데이터들의 범위 |
| length() | 값들의 개수(길이) |


매개변수
매개변수는 입력값을 의미하는데, 여기에서 매개변수의 이름을 매개변수 명, 입력하는 값을 매개변수 값이라고 한다.
ex)
sort(x=d, decreasing=T) => 여기에서 매개변수 이름은 x와 decreasing이고 매개변수 값은 d와 T가 된다.
또한 보통 매개변수의 이름은 생략이 가능하다.
ex)
sort(d, T) => 가능
sort(x=d, T) => 가능
sort(d, decreasing=T) => 가능
벡터에 논리 연산자 적용
| 연산자 | 사용 예시 | 설명 |
| < | A<B | B가 A보다 크면 TRUE |
| <= | A<=B | B가 A보다 같거나 크면 TRUE |
| > | A>B | A가 B보다 크면 TRUE |
| >= | A>=B | A가 B보다 같거나 크면 TRUE |
| == | A==B | A와 B가 같으면 TRUE |
| != | A!=B | A와 B가 다르면 TRUE |
| | | A|B | A또는 B어느 한 쪽이라도 TRUE이면 TRUE |
| & | A&B | A와 B모두 TRUE이면 TRUE |
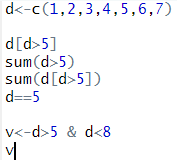
- d [d>5]: d보다 큰 데이터들을 출력
- sum(d>5): TRUE는 1을 의미하고 FALSE는 0을 의미하기 때문에 d보다 큰 숫자의 개수를 의미
- sum(d [d>5]): 5보다 큰 숫자들의 합을 의미
- d>5 & d <8: 5보다 크고 8보다 작은 데이터를 TRUE, 아니면 FALSE로 v에 저장

리스트와 팩터
리스트
- 리스트: 서로 다른 자료형의 값들을 저장하고 다룰 수 있도록 해주는 수단
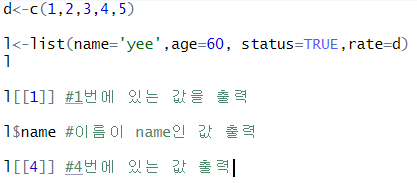

- list()를 이용하여서 여러 자료형의 데이터를 저장가능함
- n번쨰 데이터에 접근하고 싶다면 d [ [n] ]의 형태로 접근 가능
- $+이름으로 사용하면 이름에 있는 데이터에 접근할 수 있음
위의 그림 4번 데이터처럼 여러 개의 데이터가 있는 경우에 하나의 값을 추출하고 싶다면
l[[4]] [n]의 형태로 4번째 벡터의 n 번째 데이터에 접근할 수 있다.
팩터
- 팩터: 벡터의 일종으로 범주형 자료를 저장하는 데 사용된다.
- 범주형 자료: 성별, 혈액형 등의 범주로 구분할 수 있는 데이터로 구성된 자료를 의미한다.


- 벡터와 팩터의 다른 점은 큰 따옴표의 유무와 Levels로 혈액형의 종류를 알려준다.
- levels와 같은 경우는 저장된 종류를 출력해 준다.
- as.integer()와 같은 경우는 종류를 숫자로 변경하여서 d를 출력해 준다.
- 단 데이터를 추가하는 경우에는 다른 종류의 데이터가 추가된다면 NA처리된다.
'확률 통계 > R 데이터 분석' 카테고리의 다른 글
| (Ch 6) 반복문 (2) | 2024.08.25 |
|---|---|
| (Ch 5) 조건문 (0) | 2024.08.25 |
| (Ch 4) 매트릭스와 데이터프레임 (2) | 2024.08.25 |
| (Ch 2) R 실행 해보기 (0) | 2024.08.17 |
| (Ch1) R 준비 과정 (2) | 2024.08.16 |